It is increasingly common to come across reference to the practices of de-identification, encryption & anonymisation in digital advertising, so we are keen to provide some background, definitions, examples and recommendations related to all three.
All three methods look to provide balance between privacy and personalisation, whilst complying with global regulations and still providing value to both users and marketers.
However, many of the details vary – not only between these different approaches, but between the different types of methods that exist within De-identification, Encryption & Anonymisation.
Why is this Topic Important?
Leveraging data protection strategies for personalised experiences such as advertising are increasingly critical, due to a number of key converging factors that have been rapidly evolving over the past decade or so.
We’ve seen these factors highlighted consistently in our annual ‘Data Advertising: State of the Nation Reports‘. To access the 2024 version please CLICK HERE
Privacy Concerns & Global Regulations
Growing public awareness and concerns about privacy, data breaches, and the misuse of personal information has resulted in increased demand for transparency and controls over how consumer data is being used. As a result companies are actively looking to adopt more privacy-enhancing solutions in order to maintain trust and customer loyalty.
Additionally this push for consumer privacy has resulted in various data protection regulations around the world mandating far stricter controls and over personal data and how it is being utilised. These may laws vary slightly in different markets, but consistently require that personal data be handled in ways that respect user privacy – making solutions such as de-identification, encryption, and anonymisation essential for legal compliance purposes.
AdTech Industry Changes
Advertising technologies have for some time now been working with ongoing signal loss (including increased third-party cookie deprecation and falling iOS opt-in rates) resulting in a loss of scale in addressability. Hence industry and ad tech vendors are actively working collaboratively to help buyers and sellers navigate a fragmented landscape of different privacy-preserving proposals across different web browsers and within in-app environments.
The importance and popularity of first-party data has grown, which requires far more robust privacy measures. Encryption ensures that this data remains secure, while de-identification or anonymisation can be used for broader, less invasive ad-targeting and personalisation.
Brand Reputation & Ethical Advertising
Consumer sentiment plays an important part in enabling businesses to build trust with privacy-conscious consumers who increasingly expect ethical advertising practices to be followed in terms of data collection, management and activation.
Security concerns also play a part here as we are seeing data breaches and cyber threats evolve which erode consumer trust in how organisations handle sensitive data that has been shared. Encryption in particular has become crucial in securing personal data against unauthorised access both when in storage and during transmission.
Technological Advancements & Data Utility
A paradox exists between consumer demand for effective personalisation and targeted advertising as these ultimately will rely upon some form of collecting and analysis of user data, and that data being usable depending upon requirements. This need creates an inherent tension with privacy, resulting in companies looking to find ways to deliver relevant and engaging experiences without compromising user privacy.
De-identification, encryption, and anonymisation can provide tools to navigate this delicate balance, along with other technical advances such as PETs (Privacy-Enhancing Technologies) & AI.
- AI – is being used more and more in ad personalisation, demanding a need to feed AI systems with data that genuinely respects privacy. Techniques that ensure AI can learn from data without compromising privacy are required as a result.
- PETS – (Privacy-Enhancing Technologies) are advancing, making it more feasible to implement these methods at scale. Innovations in differential privacy, homomorphic encryption, and secure multi-party computation provide new ways to personalise experiences whilst safeguarding data.
To read more about PETs review the further info below or else simply CLICK HERE
Definitions
Terms such as de-identification, encryption & anonymisation are constantly being used to describe a range of different methods and approaches – so it’s important to start with some general definitions. In the following sections we’ll dive into further details for each and will also provide some meaningful examples to try and bring each method to life.
De-identification – a process of removing, altering or obscuring direct identifiers from data containing personal information, so that individuals cannot be directly identified.
Encryption – a process which involves converting or transforming data into an unreadable format or code using a key, so as to prevent unauthorised access. Only an authorised user, with the decryption key, can reverse the process and access the original data.
Anonymisation – a process where no risk of exposing or sharing data is utilised, or else any data leveraged is irreversibly altered or transformed in such a way that it is impossible to identify individuals from the dataset or through linkage with other data. Both approaches eliminate any possibility of personal information exposure or re-identification.
| De-identification | Encryption | Anonymisation | |
| Core Focus: |
Protection of user identity. | Confidentiality and user access controls. | Avoid or mitigate any risk of consumer identification. |
| Pros: | Low effort & high data utility. | High protection & high utility with competent partners. | Very high level of privacy protection. |
| Cons: | Some risk of re-identification remains. | Higher effort and partnerships may be more limited. | Potentially reduced data utility. |
This is a very general set of definitions, designed to introduce each approach – for more details for each please see the below sections.
De-identification: Further Info & Working Examples
De-identification modifies or obscures data to reduce any risks of revealing an individual’s identity while still allowing for meaningful analysis, activation and personalisation. Many regulations, such as the GDPR in Europe, require that data to be de-identified before it can be used for certain purposes such as delivering ads, research or analytics.
Some examples are shown below, but most regularly this is done by reducing the precision of data, removing fields that contain identifiers, adding noise to obscure true values, masking certain elements (e.g. an IP address of 192.168.1.1 could be masked to 192.168.x.x) and replacing real identifiers with fake identifiers or pseudonyms.
However, risks do remain with using de-identification approaches – as data can sometimes still be re-identified when combined and reverse-engineered with external datasets or even publicly available information such as voting rolls, social media profiles, or online databases.
Common examples include:
Hashing – transforms direct identifiers (such as an email address) into a unique string of characters by using a dedicated standardised algorithm, or ‘cryptographic hash function’. This transformation process is designed to be one-way and irreversible – so once the email address has been hashed, it cannot be reverted back to its original form. Different types of hashed algorithms exist – such as MD5, SHA-1, SHA-2, SHA-256, and even SHA-384. Each produces different hash values, depending upon requirements.
Hashing is commonly used in data-driven advertising to identify users for targeting, optimisation and measurement without having to directly leverage personal information. Different legislations can vary on whether a hashed identifier such as an email address still has to be treated as personal information, and consumer consent will often have to be requested prior to collection (for example as per GDPR in Europe).

Differential Privacy – is a mathematical framework designed to ensure that the inclusion or exclusion of any single individual’s data in a dataset does not significantly affect the outcome of any analysis performed on that dataset. As a result data can be used in ways that were previously deemed too risky from a privacy perspective, by providing a mathematical assurance that individual privacy is maintained within a controlled framework.
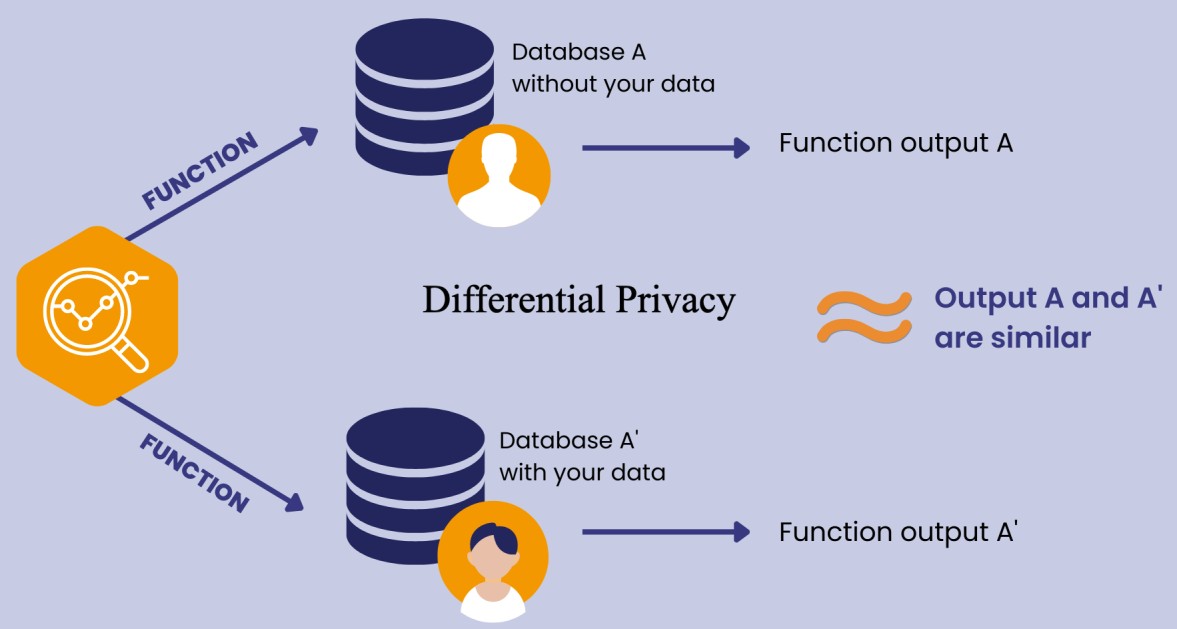
Not feasible with smaller data sets, but Differential Privacy is becoming an increasingly common as a tool with larger platforms and tech vendors that regularly handle massive amounts of data. To read further comprehensive guidance from IAB Tech Lab on the use Differential Privacy in digital advertising click here
K-anonymity – where data is aggregated into a group with a minimum privacy threshold – meaning information in the group could correspond to any single member, thus masking the identity of the individual or individuals in question. Approaches of generalisation and/or suppression can be leveraged in order to achieve threw desired level of ‘k-anonymity’. This approach features in Google’s Privacy Sandbox proposals, such as the Protected Audience API. To read more about the Privacy Sandbox proposals simply CLICK HERE and to see how to start testing Google’s Protected Audience API in OpenRTB (via a community extension) simply CLICK HERE
Encryption: Further Info & Working Examples
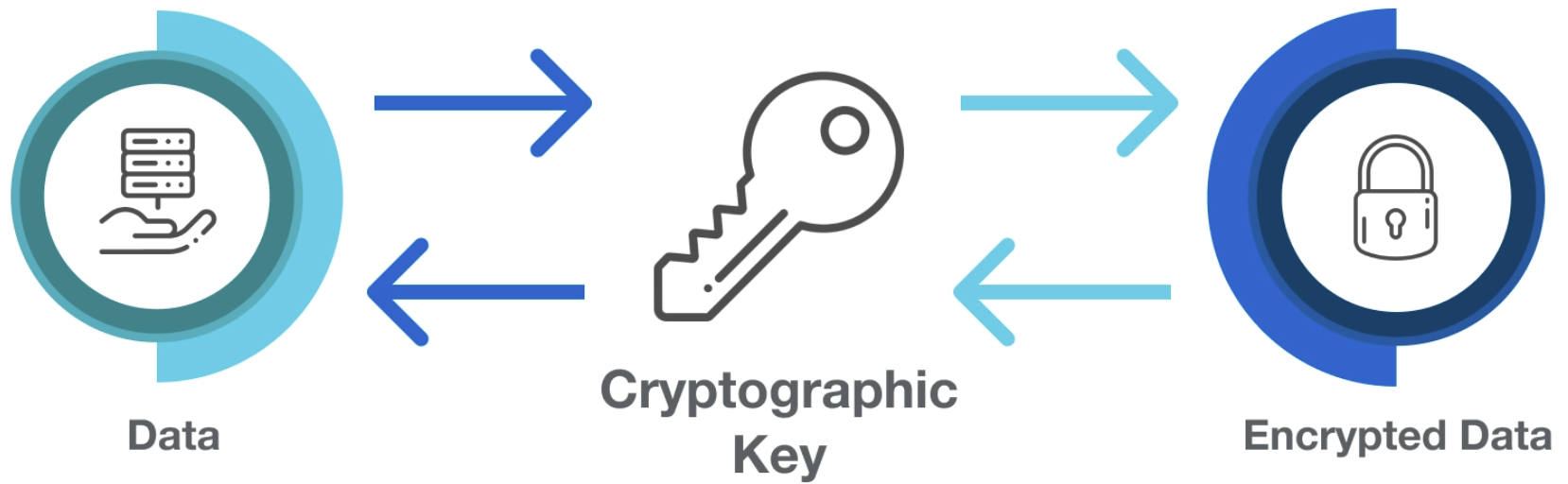
Encryption practices are not designed to make data anonymous, but instead to keep data confidential and secure during collection, storage, and transmission.
Encryption is commonly used by ad tech vendors to protect data when stored in databases (at rest) or when being transmitted between systems (in transit).
 Some common examples include:
Some common examples include:
HTTPS / TLS – Hypertext transfer protocol secure (HTTPS) is the secure version of HTTP, which is the primary protocol used to send data between a browser and a website. HTTPS uses TLS (Transport Layer Security) to establish an encrypted connection to an authenticated peer over an untrusted network. Earlier, less secure versions of this protocol were called Secure Sockets Layer (SSL).
Serving Ads & RTB Encryption – it is now increasingly common practice for ad servers to deliver secure ads into HTTPS sites by leveraging encryption to ensure that any communication between a website and the ad server is secure. Additionally, in RTB (real-time bidding) auctions, encryption protects the confidentiality and integrity of bidding information such as bid requests, bid responses and pricing & targeting criteria.
Trusted Execution Environment (TEE) – allows data to be processed within a secure piece of hardware that uses cryptographic protections creating a confidential computing environment that guarantees security and data privacy during data processing.

An example of this in digital advertising is (as shown above) is the confidential matching feature within Google Ads Data Manager – which processes data within a Trusted Execution Environment, enabling advertisers to match their customer data with Google’s data without ever directly sharing any sensitive information.
Secure Multi-Party Computation (MPC) – allows multiple parties to jointly compute a function over their inputs while keeping those inputs private from each other. The goal is to ensure that only the output of the computation is revealed, not the individual inputs and is becoming increasingly common in data driven digital advertising.
A very real-world example of leveraging MPC capabilities was the ‘Privacy-Preserving Contact Tracing‘ initiative jointly run by Apple and Google (click here for more info) to help trace and contain the spread of coronavirus during the pandemic (as per image below).
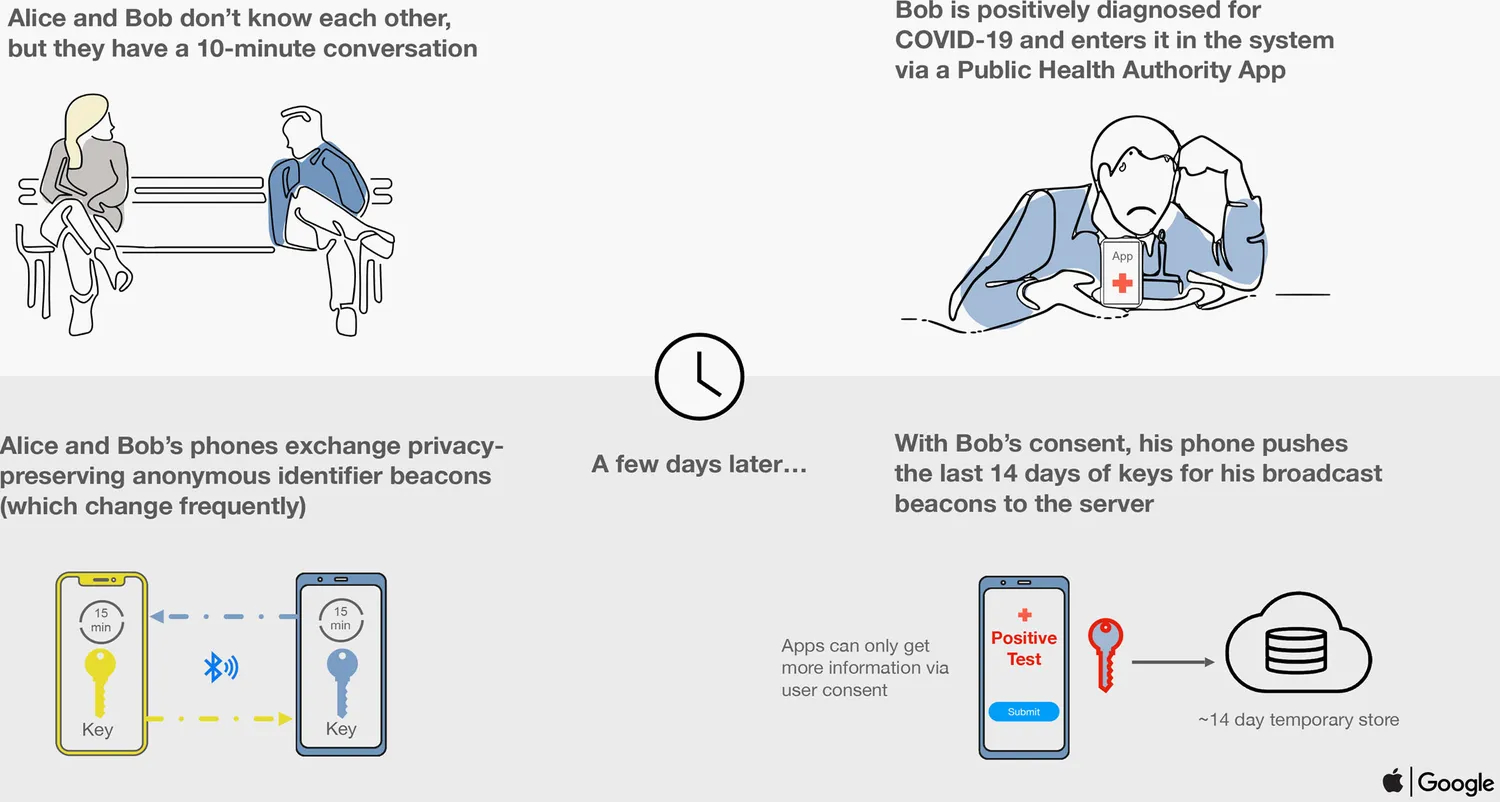
In digital advertising, Data Clean Room solutions commonly leverage MPC enabling different parties to combine or compare datasets for analysis (audience matching and/or campaign performance) without ever revealing the underlying data to one another. Each party’s data remains fully private, with only the insights of the various resulting computations ever being shared.
Also, Meta’s Private Lift and Private Attribution measurement tools leverage MPC (and encrypted data) to help advertisers understand how their ads perform. These tools allow marketers to gather insights about their campaigns without ever sharing consumer-level data.
Homomorphic Encryption – is a form of encryption that allows computations to be performed on encrypted data without having to decrypt it. This enables users to process data in its encrypted form, and the result of these computations, when decrypted, is the same as if the operations had been performed on unencrypted data.
This is approach is commonly used in voting – for an example click here to read more about Microsoft’s not for-profit ElectionGuard solution which leverages homomorphic encryption to protect the privacy of elections in the US.
Anonymisation: Further Info & Working Examples
The more you anonymise data, the less useful it becomes for precise targeting. Hence, fully anonymised data is particularly challenging in advertising due to the inherent tension between its utility for meaningful targeting, optimisation & measurement / insights whilst genuinely ensuring that no individual can ever be identified.
Even with many of the de-identification and partial anonymisation techniques summarised above, there can often be enough residual information in datasets that, when combined with external data, could potentially lead to re-identification. This is especially true with large datasets where unique combinations of data points could technically pinpoint individuals. Also, as technology and data analysis techniques improve, methods of de-anonymising data also naturally evolve, making previously thought secure & anonymised data potentially vulnerable to new attacks.
That said, there are privacy-preserving approaches such as contextual advertising that never leverage any sensitive data and techniques such as federated learning that offer promising approaches to leveraging fully anonymised data whilst still enabling valuable insights.
Contextual Advertising – is entire safe and never leverages any form of personal information about a consumer. It is the practice of delivering ads only relevant to the content being consumed and the contextual environment that the user is in during that session. It’s less about the demographic profile of the user, their past browsing behaviours, known interests and previous interactions. The standard approach is to have both category-based and keyword-based contextual targeting.
Keyword contextual targeting deliver ads targeted to pages that match specific keywords, whilst category-based contextual ads are targeted to those pages that fall into predetermined categories – preferably based upon the IAB Tech Lab content taxonomy which is constantly being updated.
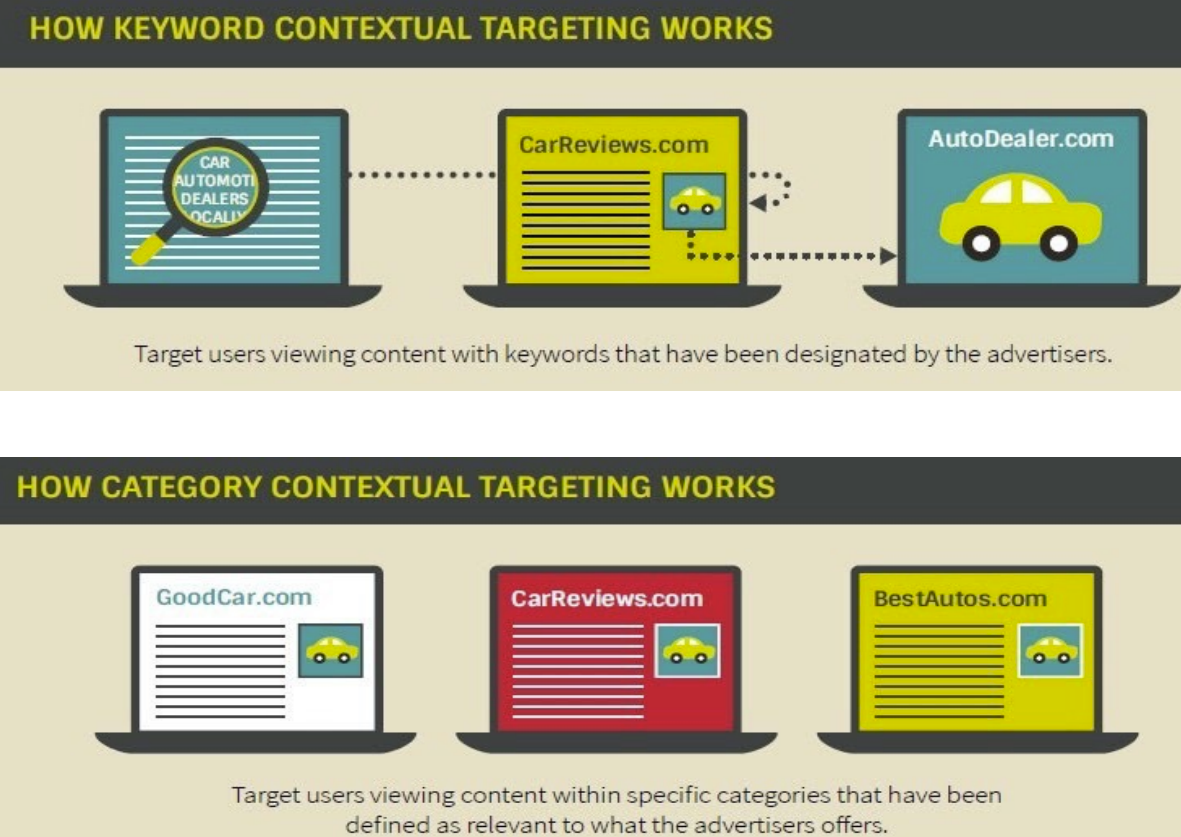
The more proficient your systems are at understanding the true underlying context of a page and its content, the better your ad matching capabilities will be. Also these practices are ever-evolving with deeper semantic analysis and targeting, as opposed to simply utilising simple keywords, incorporating more complex taxonomies and natural language processing.
For further guidance review the IAB Australia Contextual Targeting Handbook simply CLICK HERE
Curated Audiences – formerly known as Seller Defined Audiences, is an addressability specification developed by IAB Tech Lab, designed to allows publishers, DMPs and data providers to leverage data responsibly and reliably without any data leakage, linkage, exposure or reliance on deprecated IDs and/or new, untested technologies.

As a result, as long as the sell-side data collection and management practices are fully competent, any resulting advertising activity remains fully privacy safe as no user data is ever exposed. Instead, users are grouped into anonymous segments and each user within a segment is treated identically for targeting purposes.
To learn more about IAB Tech Lab’s Curated Audiences simply CLICK HERE
Federated Learning – is a machine learning approach that allows multiple participants to collaboratively train a model without ever sharing any raw data. In the context of advertising, Federated Learning can be applied in several innovative ways to enhance user privacy while still benefiting from data-driven insights.
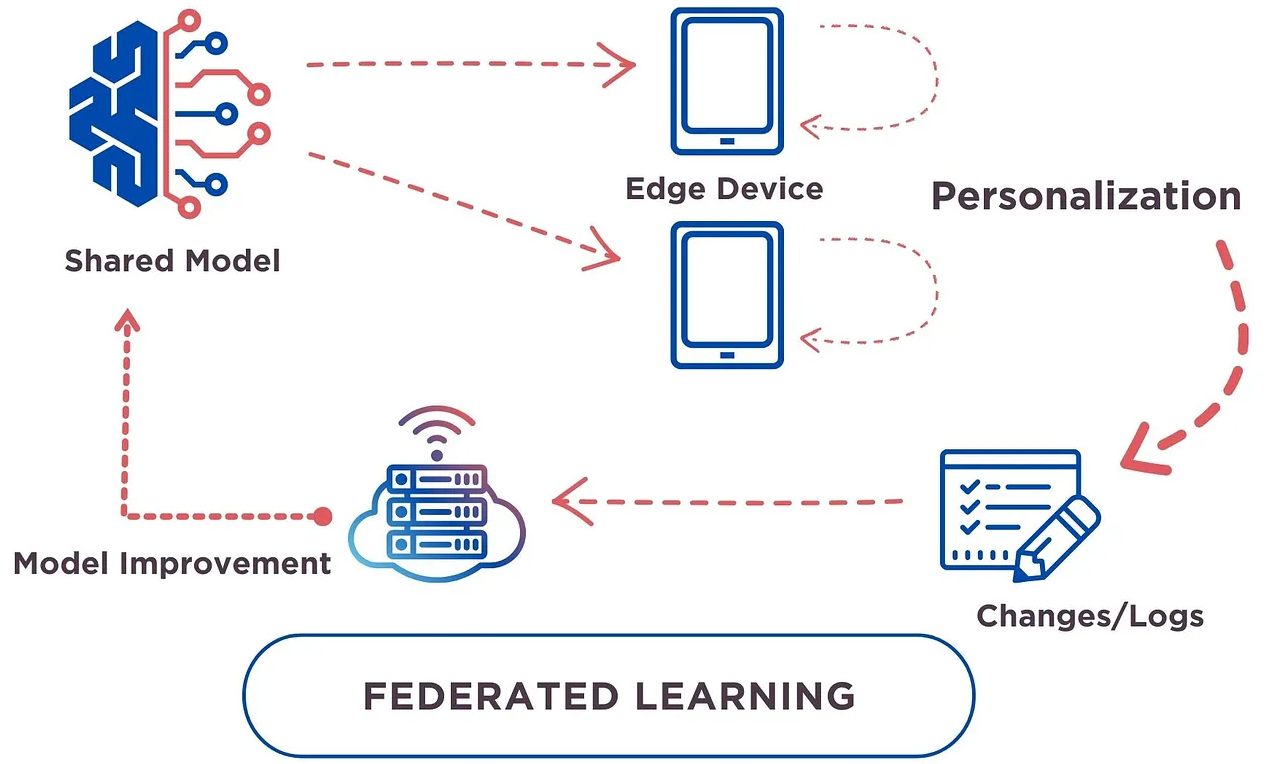
So, rather than ever collecting or sharing any data on a central server, machine learning models are downloaded to individual devices. These models are then trained on the data already present on the device, which is held securely. Then only the resulting insights & parameters are sent back to a central server, which can then aggregate the insights from multiple devices to ultimately create a more accurate and generalised global model for more personalised ad targeting and/or measurement.
Examples of PETs Currently in use For Digital Advertising

image source: ThinkMedium
Best Practices & Recommendations
Overall, it’s very likely that a combination of some or even all of the methods above will be commonly leveraged moving forwards. Particularly as Australia is going through a Privacy Review process and we expect to see draft legislations impacting data practices for advertising sometime in 2025.
Businesses might look to encrypt data for transmission, de-identify for initial analysis, and then anonymise before sharing or using in scenarios where privacy is non-negotiable. This more layered approach can help to balance personalisation with privacy.
Regardless, it’s worth approaching discussions on this topic with some clarity on exactly what is meant by the various terms being used and approaches being taken. Some suggested questions are below for you to consider:
Do we have a clear policy on the lifecycle of any personal data we leverage from collection to management and/or deletion?
How do we ensure that all sensitive advertising data is encrypted, including both user data and internal campaign data?
What type of encryption is currently in use for data at rest and data in transit?
Do we conduct periodic re-identification risk assessments?
How do we ensure that de-identified data cannot be re-identified when combined with other data sources?
How do we measure the effectiveness of our privacy measures in terms of both user trust and data utility for advertising?
How do we educate our people about data handling, privacy, and security best practices?
Have we established protocols for responding to data breaches or privacy violations involving de-identified or encrypted data?
Are we leveraging the latest and best technologies and tools to enhance our data privacy and security?
Are we transparent with consumers about how we use, protect, and anonymise their data?
How are we providing users with control over their data?
What’s our strategy for adapting to new technologies or regulatory changes that might affect data privacy practices?
Are there third-party audits or certifications that validate our data protection practices?
How do we manage consent for data usage, especially in the context of anonymisation and de-identification?